
我們在前面五天中,介紹了機器學習生命週期的五個步驟,在 Step 5. 檢查模型表現時,如果發現模型表現退步,可以退回去 Step 2 重新蒐集資料、或是檢查資料標記的一致性,也可以退回去 Step 3. 重新訓練模型或調整演算法。
這兩個策略都能夠提升模型的表現,也各有其優勢和適合的應用場景,而究竟要選擇哪一個策略,通常取決於問題的具體需求,這也是 model-centric 和 data-centric 思考方式的差異。
簡單來說,這兩個思考方式的差異如下:
接下來讓我們仔細地介紹這兩種思考方式吧!
在模型導向(model-centric)的思維中,資料集通常是固定的。如同在 Kaggle 的比賽一樣,我們的目標是使用既定的資料集,不斷優化模型架構和參數,讓模型能夠在這些數據上達到最佳表現。這個方法的核心是圍繞模型本身進行調整和改進,隨著不斷迭代,模型可以變得更為複雜,或選擇更有效的演算法來解決問題。
通常會分為三個步驟:
其中,第二步和第三步會不斷地一直循環,逐步調整模型,讓模型在固定資料集上達到最好的表現。
然而,這個方法其實有一個問題,如同在 Step 2 提過的,資料標記的一致性是非常重要的,如果資料集的品質本身存在問題,即使模型的演算法再適合,也無法提升表現,因為根本問題沒有被解決。
因此,Andrew Ng 提出一個概念:From Big Data to Good Data,他說以前大家都致力於蒐集許多資料,在固定資料集上,花很多時間,想辦法使用不同的模型、演算法來提升表現。而他建議我們也可以嘗試優化自己的 data,而非只是專注在改善模型,而這就是資料導向(data-centric iteration)的思維邏輯。
與模型導向的思考方式不同,資料導向的迭代策略強調資料品質的重要性。這個方法認為模型成功的關鍵是高品質的資料集,優化模型固然重要,但是改善數據品質可以更大程度地提升模型性能。如下圖所示,Andrew Ng 表示在不同的機器學習任務中,使用資料導向的思考方式,比起模型導向,能夠更大幅度地改善模型表現。
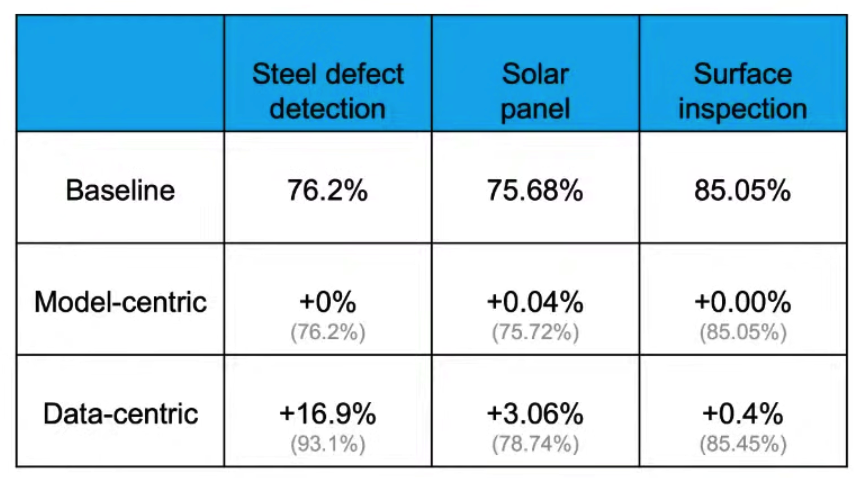
圖片來源:A Chat with Andrew on MLOps: From Model-centric to Data-centric AI | DeepLearningAI
因此,他建議我們可以將重心放在資料品質上,提升數據標記的準確性和一致性,進而使多種模型都能夠在相同資料集上表現良好。Andrew 認為資料集就如同模型的食材,要先有好的原料,才能夠烹調出一頓佳餚。即便烹飪技巧再好,食材如果品質低下,也是沒有辦法得到有好吃的一餐。
資料導向一樣分為三個步驟:
建立一個 baseline model:這個方法也會先建立一個 baseline model,有助於衡量數據變化對模型的影響。
數據迭代(data iteration):這是資料導向策略的關鍵步驟,根據模型的表現來調整數據,而不是不斷改變模型。舉例來說,可以透過錯誤分析(error analysis),檢查模型在不同資料標籤上的表現,再評估要改善哪一個標籤的資料品質;或是透過(data augmentation),增加資料量來改善模型的泛化(generalization)能力;另外,也可以檢查資料標籤的一致性,確保資料的乾淨程度。
評估並改善資料:每一次資料改進後,都要重新評估模型表現。如果發現某些類別的預測能力不好,可能需要針對該類別增加一些資料。
資料導向的優點在於它能夠處理很多模型無法解決的問題,特別是當資料本身存在品質問題時。透過改善數據,即便使用簡單的模型,也能獲得良好的表現。
雖然我們這篇看起來是在讚揚資料導向的策略有多優秀,不過,在機器學習專案中,模型導向和資料導向並不是互斥的關係,我們可以根據情況結合這兩個方法。例如,可以先從資料導向的思考方式出發,確保資料集的品質,再進行模型的優化。如果出現 data drift 或 concept drift 的問題(參考 Day 7 的介紹),可以再回頭調整資料集,如此一來,便可以讓我們在不斷變化的真實世界中保持模型的穩定性和準確性。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference
